source: https://ai.gopubby.com/agentic-rag-with-llama-index-multi-step-reasoning-capability-03-fd0419c86fd5
Notes
Origin
Welcome back to the third installment of our Agentic RAG series! In this article, we’ll tackle the single-shot prompt limitation we discussed previously. So far, our focus has been on single-shot prompting, where tasks are completed in a single loop. However, when it comes to complex tasks that require multi-step reasoning, this approach falls short. This is where agents shine, particularly in the context of LLMs and Agentic RAG applications.
欢迎回到 Agentic RAG 系列的第三篇!在本文中,我们将讨论之前讨论过的单次提示限制。到目前为止,我们的重点是单次提示,即在一个循环中完成任务。然而,当涉及到需要多步推理的复杂任务时,这种方法就显得力不从心了。这正是代理的优势所在,尤其是在 LLMs 和代理 RAG 应用中。
In this article, we’ll explore how to implement a multi-step reasoning loop in our Agentic RAG architecture. Get ready for an exciting deep dive into the power of agents and their ability to handle intricate, multi-step tasks with precision and efficiency.
在本文中,我们将探讨如何在我们的 Agentic RAG 架构中实现多步推理循环。准备好深入了解代理的强大功能及其精确高效地处理错综复杂的多步骤任务的能力吧。

Image By Code With Prince
图片来源:Prince 代码
What Are Agents 什么是代理
So far we have been looking at working with Llama-index.
到目前为止,我们一直在研究如何使用 Llama-index。
Data Agents are LLM-powered knowledge workers in LlamaIndex that can intelligently perform various tasks over your data, in both a “read” and “write” function. They are capable of the following:
数据代理是 LlamaIndex 中由 LLM 驱动的知识工作者,可以通过 “读 “和 “写 “两种功能智能地执行各种数据任务。它们具有以下能力:
Perform automated search and retrieval over different types of data — unstructured, semi-structured, and structured.
对不同类型的数据(非结构化、半结构化和结构化)执行自动搜索和检索。
Calling any external service API in a structured fashion, and processing the response + storing it for later.
以结构化的方式调用任何外部服务应用程序接口,处理响应并存储以备后用。
In that sense, agents are a step beyond our query engines in that they can not only “read” from a static source of data, but can dynamically ingest and modify data from a variety of different tools.
从这个意义上说,代理比我们的查询引擎更进一步,因为它们不仅可以从静态数据源中 “读取 “数据,还可以从各种不同的工具中动态地获取和修改数据。
Building a data agent requires the following core components:
建立数据代理需要以下核心组件:
A reasoning loop 推理循环
Tool abstractions 工具抽象
A data agent is initialized with set of APIs, or Tools, to interact with; these APIs can be called by the agent to return information or modify state. Given an input task, the data agent uses a reasoning loop to decide which tools to use, in which sequence, and the parameters to call each tool.
数据代理初始化时有一组应用程序接口(API)或工具(Tools)与之交互;代理可以调用这些应用程序接口来返回信息或修改状态。给定输入任务后,数据代理会使用推理循环来决定使用哪些工具、使用顺序以及调用每个工具的参数。
By default agents in Llama-index are made of two main things: 默认情况下,Llama-index 中的代理主要由两部分组成:
-
AgentRunner: This is the part of the agent that deals with the task orchestration aka Task Orchestrator. This section of the agent also handles State and Memory. The AgentWorker responds back to this section of the agent after completing each task allocated to it, the response is then communicated back to the user if there is a need.
代理运行器(AgentRunner):这是代理中处理任务协调的部分,又名任务协调器(Task Orchestrator)。这部分代理还处理状态和内存。AgentWorker 在完成分配给它的每项任务后,都会向代理的这一部分做出响应,然后在需要时将响应反馈给用户。
-
AgentWorker: This is what actually executes and reasons for tasks. Tasks are delegated to this section of the agentic workflow by the AgentRunner. This deals with the Tools and LLMs.
AgentWorker:这是任务的实际执行和原因。任务由 AgentRunner 委托给代理工作流程的这一部分。这部分处理工具和 LLMs.
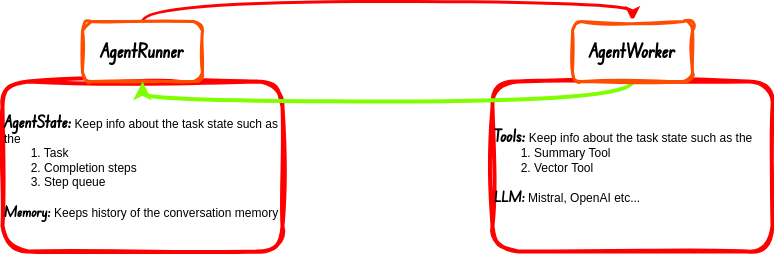
Image By Code With Prince
图片来源:Prince 代码
Video Resource 视频资源
If you enjoy watching videos rather than reading, I got you covered as well.
如果你喜欢看视频而不是阅读,我也为你提供了视频资源。
Environment Setup 环境设置
We’ll be using the same environment we had setup from last article. The only thing I’ll create is an .ipynb file, this file is called Lesson_03.ipynb :
我们将使用上一篇文章中设置的相同环境。唯一要创建的是一个 .ipynb 文件,该文件名为 Lesson_03.ipynb :
Image By Code With Prince
图片来源:Prince 代码
Creating Tools 创建工具
We’ll go ahead and create two main tools as we have already done in the last articles.
我们将继续创建两个主要工具,就像我们在上一篇文章中所做的那样。
import dotenv
%load_ext dotenv
%dotenv
import nest_asyncio
nest_asyncio.apply()
from llama_index.core import SimpleDirectoryReader
# load lora_paper.pdf documents
documents = SimpleDirectoryReader(input_files=["./datasets/lora_paper.pdf"]).load_data()
from llama_index.core.node_parser import SentenceSplitter
# chunk_size of 1024 is a good default value
splitter = SentenceSplitter(chunk_size=1024)
# Create nodes from documents
nodes = splitter.get_nodes_from_documents(documents)
from llama_index.core import Settings
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
# LLM model
Settings.llm = OpenAI(model="gpt-3.5-turbo")
# embedding model
Settings.embed_model = OpenAIEmbedding(model="text-embedding-ada-002")
from llama_index.core import SummaryIndex, VectorStoreIndex
# summary index
summary_index = SummaryIndex(nodes)
# vector store index
vector_index = VectorStoreIndex(nodes)
# summary query engine
summary_query_engine = summary_index.as_query_engine(
response_mode="tree_summarize",
use_async=True,
)
# vector query engine
vector_query_engine = vector_index.as_query_engine()
llm = OpenAI(model="gpt-3.5-turbo", temperature=0)
from llama_index.core.tools import QueryEngineTool
summary_tool = QueryEngineTool.from_defaults(
query_engine=summary_query_engine,
description=(
"Useful for summarization questions related to the Lora paper."
),
)
vector_tool = QueryEngineTool.from_defaults(
query_engine=vector_query_engine,
description=(
"Useful for retrieving specific context from the the Lora paper."
),
)
Reasoning Loop 推理循环
Reasoning Loop 推理循环
The reasoning loop depends on the type of agent. We have support for the following agents:
推理循环取决于代理的类型。我们支持以下代理:
Function Calling Agents (integrates with any function calling LLM)
函数调用代理(与任何函数调用 LLM 集成)
ReAct agent (works across any chat/text completion endpoint).
ReAct 代理(适用于任何聊天/文本完成终端)。
“Advanced Agents”: LLMCompiler (https://llamahub.ai/l/llama-packs/llama-index-packs-agents-llm-compiler?from=), Chain-of-Abstraction (https://llamahub.ai/l/llama-packs/llama-index-packs-agents-coa?from=), Language Agent Tree Search (https://llamahub.ai/l/llama-packs/llama-index-packs-agents-lats?from=), and more.
”高级代理”:LLMCompiler (https://llamahub.ai/l/llama-packs/llama-index-packs-agents-llm-compiler?from=)、Chain-of-Abstraction (https://llamahub.ai/l/llama-packs/llama-index-packs-agents-coa?from=)、Language Agent Tree Search (https://llamahub.ai/l/llama-packs/llama-index-packs-agents-lats?from=) 等。
Agent Worker 代理工人
As we talked about this earlier on, the agent worker is responsible for running all the tools and the LLMs. Let’s create an agent worker passing in all the tools we created from above:
正如我们前面提到的,代理服务器负责运行所有工具和 LLMs 。让我们创建一个代理 Worker,将上面创建的所有工具传入其中:
from llama_index.core.agent import FunctionCallingAgentWorker
from llama_index.core.agent import AgentRunner
agent_worker = FunctionCallingAgentWorker.from_tools(
tools=[vector_tool, summary_tool],
llm=llm,
verbose=True
)
agent = AgentRunner(agent_worker)
To this it out, let’s use a prompt that will require a multi-step reasoning approach to answer.
为此,我们使用一个需要多步推理才能回答的提示。
rresponse = agent.query(
"Explain to me what is Lora and why it's being used. Are existing solutions not good enough?"
)
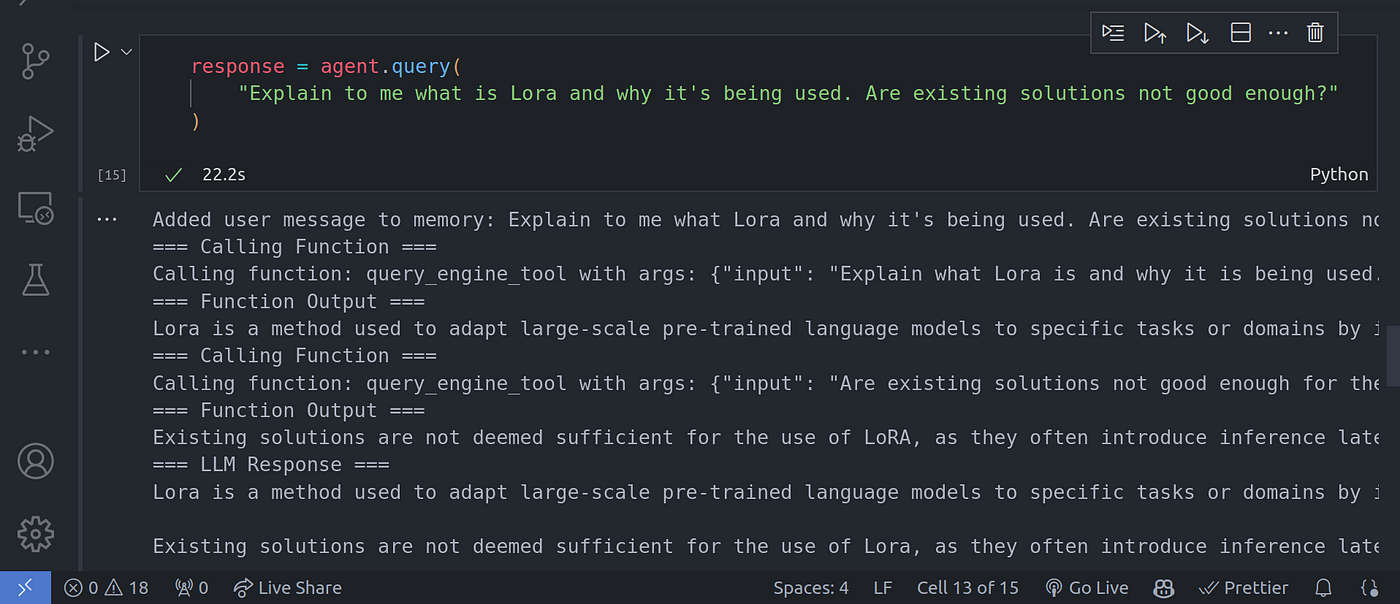
Image By Code With Prince
图片来源:Prince 代码
From the image above, you can see the LLM is making use of a chain of thought CoT reasoning to answer all the questions we had asked the LLM one after the other building on the previous.
从上图中可以看到,LLM 正在利用思维链 CoT 推理来回答我们向 LLM 提出的所有问题。
Conversation Memory 对话记忆
So far the agentic RAG architecture works well. One limitation is that it does not remember any previous conversations. We have the ability to maintain memory such that the actions the agent takes does not only depend on the user query, but also the history of the previous conversations with the agents is taken into consideration.
到目前为止,代理 RAG 架构运行良好。但其局限性在于,它无法记住之前的任何对话。我们有能力维护内存,使代理所采取的行动不仅取决于用户的查询,还考虑到代理以前的对话历史。
The memory is just a flat list of conversations the agent had with the user. This fat list is a conversational memory buffer, the reason being we don’t want to have too much of conversation being stored in memory such that we overflow context window of LLMs. This list acts as a rolling buffer depending on the context window size of the underlying LLM that we are using.
记忆只是代理与用户对话的平面列表。这个胖列表是一个对话内存缓冲区,原因是我们不想在内存中存储太多对话,以免溢出 LLMs 的上下文窗口。这个列表是一个滚动缓冲区,取决于我们正在使用的 LLM 的上下文窗口大小。
To use the memory ability of the agent, we have to call the chat() method instead of the query() method we have used so far. The query() method does not preserve state hence no conversation history is preserved.
为了利用代理的内存能力,我们必须调用 chat() 方法,而不是迄今为止使用的 query() 方法。 query() 方法不保存状态,因此不会保存对话历史。
response = agent.chat(
"Explain to me what is Lora and why it's being used. Are existing solutions not good enough?"
)
print(str(response))
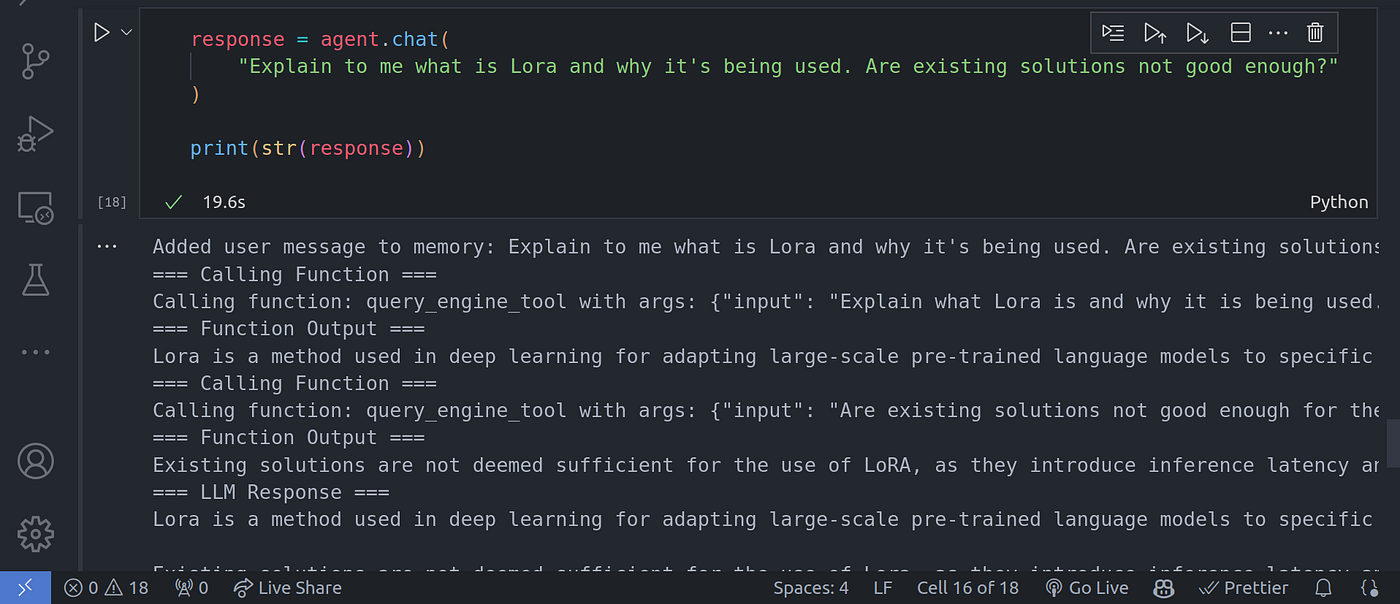
Image By Code With Prince
图片来源:Prince 代码
response = agent.chat(
"What was my last question to you?"
)
print(str(response))
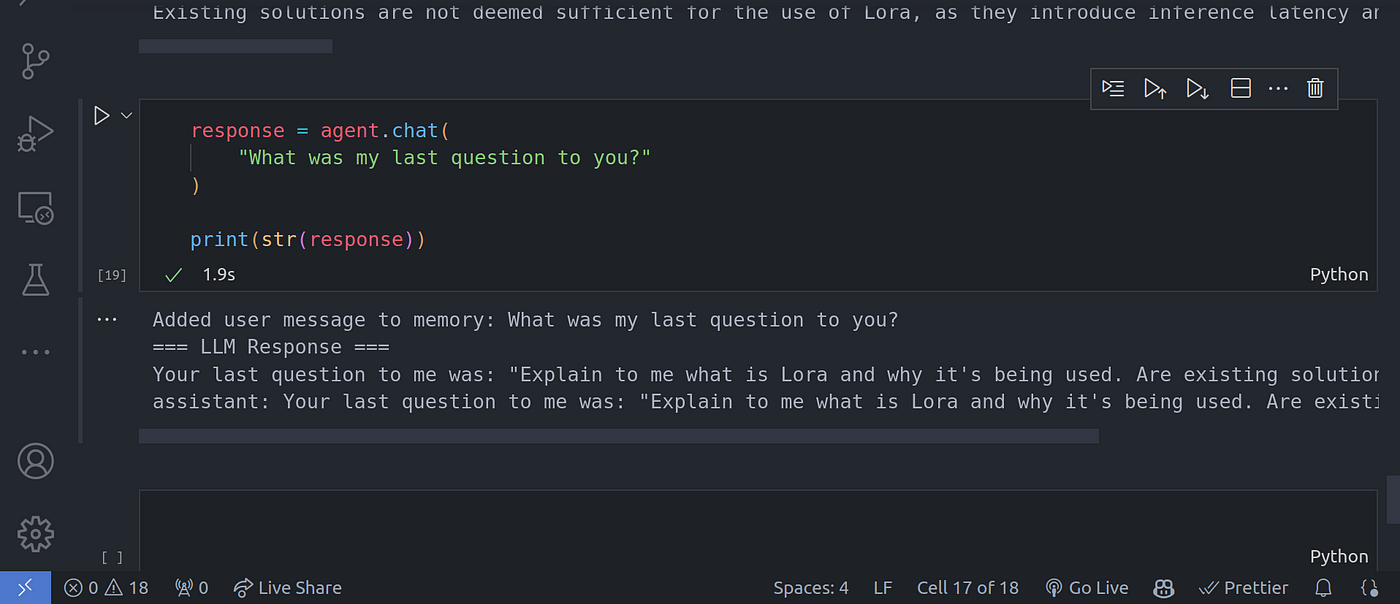
Image By Code With Prince
图片来源:Prince 代码
How It Works At A Low Level
低层次的工作原理
**We has looked into how the agent works from a high level perspective. Let’s have a look at how it works in a lower level and gain more control over the agent’s execution and how tasks are carried out. This give us some added advantage like:
我们已经从高层次的角度了解了代理的工作原理。让我们看看它在较低层次是如何工作的,从而获得对代理执行和任务执行方式的更多控制。这将为我们带来更多优势,例如**
-
Scheduling our own tasks: We can control and schedule our own tasks and set when each task will run.
安排我们自己的任务:我们可以控制和安排自己的任务,并设定每个任务的运行时间。
-
Incorporate human feedback: Understanding how the agent works at a lower level, we can be able to manually provide human feedback to the agent to let them know whether they are taking the right steps we want or not, if not we can manually specify to the agent what actions we want taken.
纳入人类反馈:在较低层次上了解代理的工作方式后,我们可以手动向代理提供人工反馈,让他们知道他们是否采取了我们想要的正确步骤,如果没有,我们可以手动向代理指定我们想要采取的行动。
-
Helps with trouble-shooting 帮助排除故障
First, let’s go ahead and create an agent runner, that we run the agent worker as we discussed earlier
首先,让我们继续创建一个代理运行程序,以运行我们之前讨论过的代理 Worker。
Image By Code With Prince
图片来源:Prince 代码
agent_worker = FunctionCallingAgentWorker.from_tools(
[vector_tool, summary_tool],
llm=llm,
verbose=True
)
agent = AgentRunner(agent_worker)
Let’s now manually create a task for the agent runner task Orchestrator:
现在,让我们手动为代理运行程序创建一个任务 Orchestrator:
task = agent.create_task(
"Explain to me what is Lora and why it's being used."
"Are existing solutions not good enough?"
)
Once we have this task created, remember we did not pass on this task to the agent worker so it’s not executed. So if we check if any task has been completed, we should get back zero, let’s see this in action:
创建任务后,请记住我们并没有将该任务传递给代理运行程序,因此它不会被执行。因此,如果我们检查是否有任务已完成,得到的结果应该是零,让我们来看看实际效果:
completed_steps = agent.get_completed_steps(task.task_id)
print(f"Number of completed steps for tasksID {task.task_id} is {len(completed_steps)}")
if len(completed_steps) > 0:
print(completed_steps[0].output.sources[0].raw_output)
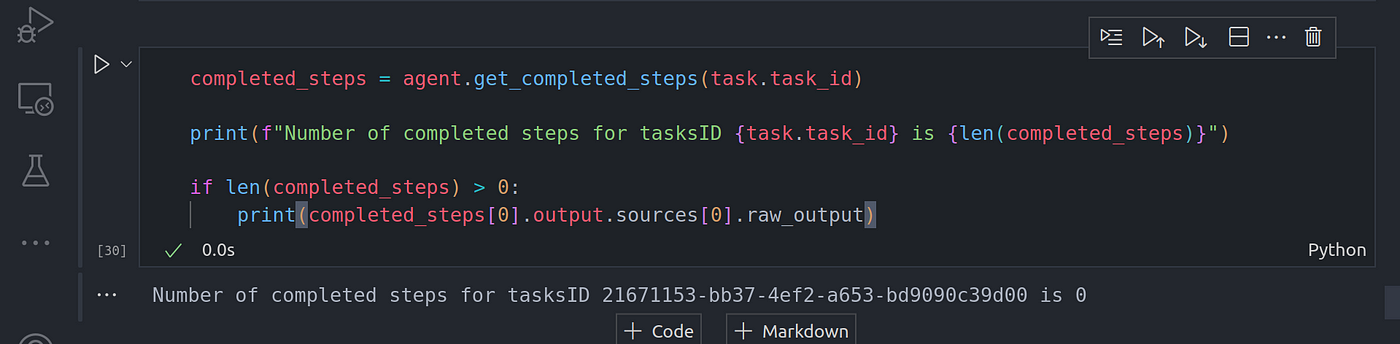
Image By Code With Prince
图片来源:Prince 代码
Now, let’s check if the agent runner has orchestrated some tasks for the agent worker to run. We can see this by viewing the upcoming tasks:
现在,让我们检查一下代理运行程序是否为代理 Worker 安排了一些任务。我们可以通过查看 “即将执行的任务 “来查看:
upcoming_steps = agent.get_upcoming_steps(task.task_id)
print(f"Number of completed steps for tasksID {task.task_id} is {len(upcoming_steps)}")
if len(upcoming_steps) > 0:
print(upcoming_steps[0].input)
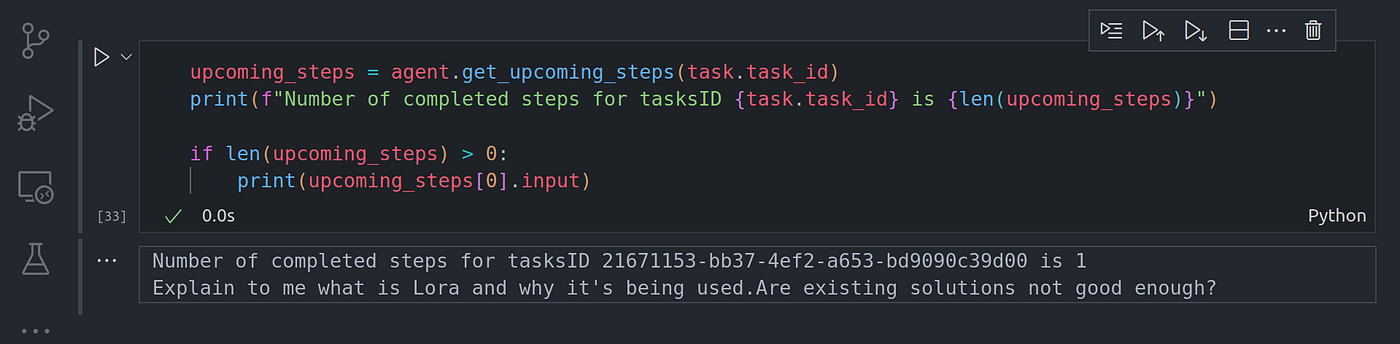
Image By Code With Prince
图片来源:Prince 代码
From here we can see the input the agent runner things should be passed down to the agent worker to execute on. The input is the original question we passed on to the task we just created.
在这里,我们可以看到代理运行程序应传递给代理 Worker 执行的输入。输入是我们传递给刚刚创建的任务的原始问题。
Now, let’s move on and execute the upcoming scheduled task to see and we get back.
现在,让我们继续执行即将到来的计划任务,看看会有什么结果。
step_output = agent.run_step(task.task_id)
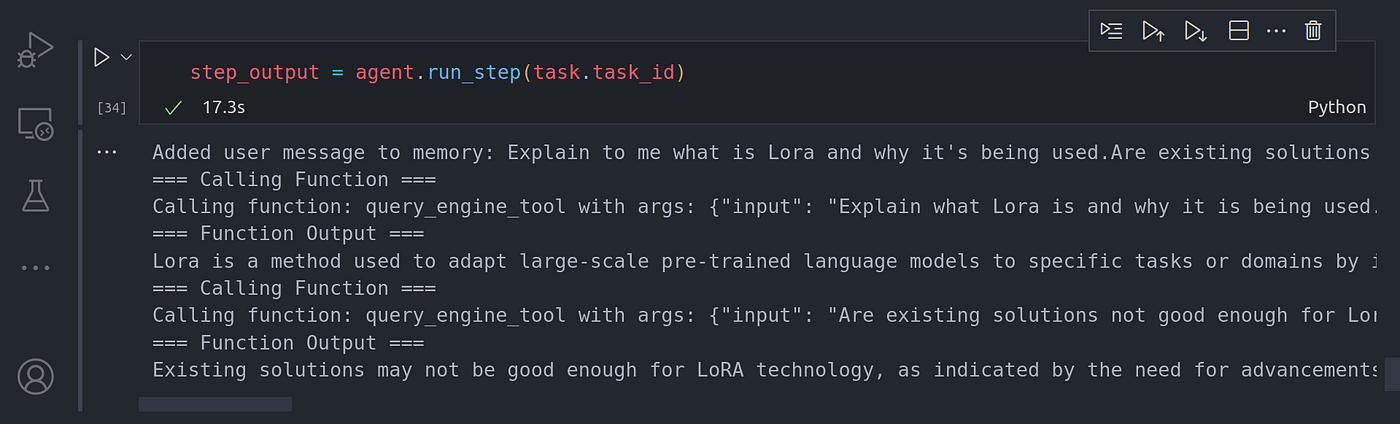
Image By Code With Prince
图片来源:Prince 代码
You can see the agent worker was able to reason over the task and identified it needed to break down the task into two separate sub-tasks. Each sub-task was solved by using tool calling aka function calling the query engine tool in this particular case.
你可以看到,代理服务器能够对任务进行推理,并确定需要将任务分解为两个独立的子任务。在这种特殊情况下,每个子任务都是通过工具调用(又称函数调用)查询引擎工具来解决的。
Once this is done, we can move on ahead to check if there are any other tasks we need to complete and what are their inputs:
完成这些工作后,我们就可以继续检查是否还有其他任务需要完成,以及它们的输入是什么:
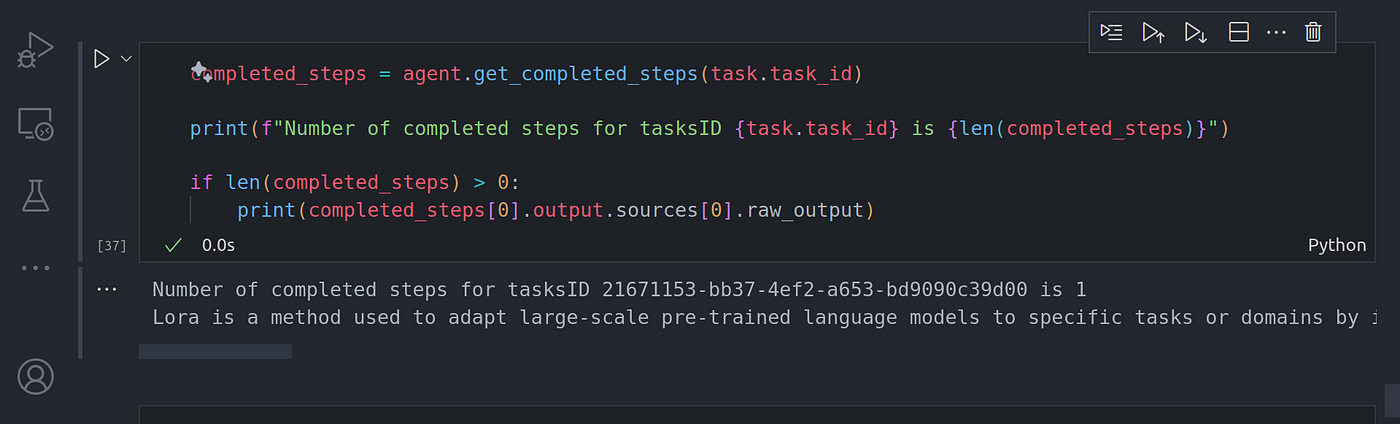
Image By Code With Prince
图片来源:Prince 代码
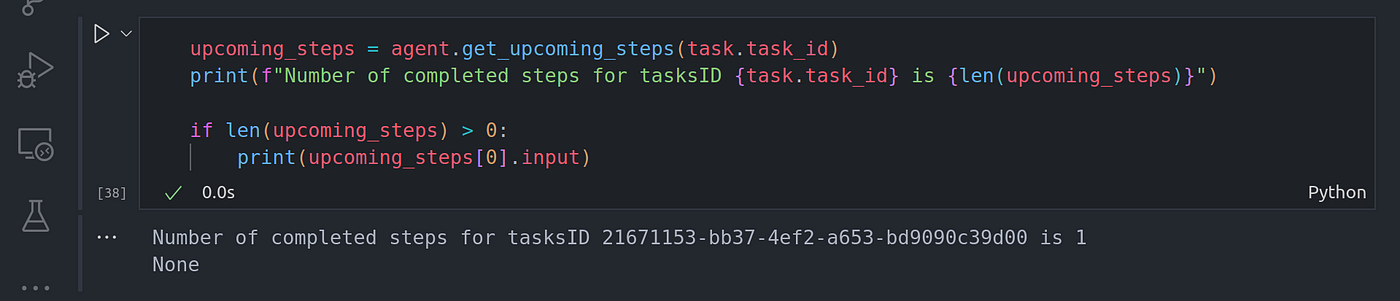
Image By Code With Prince
图片来源:Prince 代码
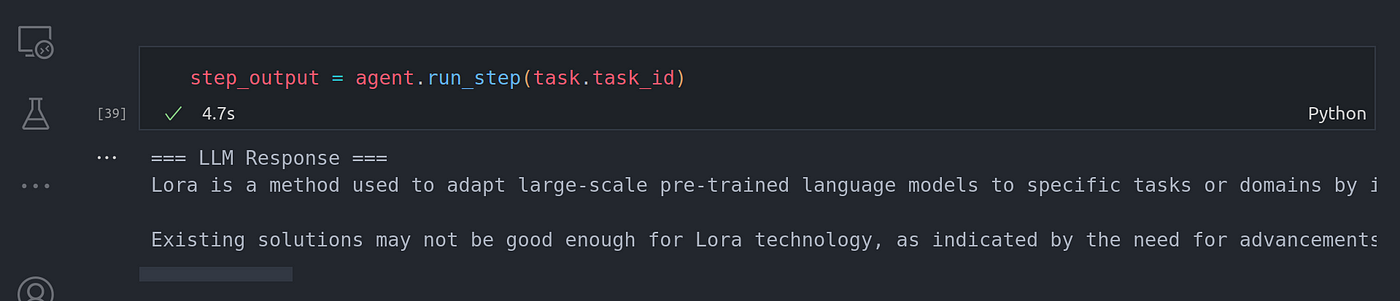
Image By Code With Prince
图片来源:Prince 代码
We can also check if this is the last step we needed to execute:
我们还可以检查这是否是我们需要执行的最后一步:
print(step_output.is_last)

Image By Code With Prince
图片来源:Prince 代码
You can see we got back True , a Python true indicating that was the last step in the task execution.
你可以看到我们得到了 True ,一个 Python true 表示这是任务执行的最后一步。
We can also override it by providing our custom tasks, this can act like a human correcting the agent on what it needed to do, a human guide feedback sort of.
我们还可以通过提供自定义任务来覆盖它,这就像是人类在纠正代理需要做什么,类似于人类的指导反馈。
To do this, I’ll create a new task, and then add human feedback in the loop and change the question of the task.
为此,我将创建一个新任务,然后在循环中添加人工反馈,并更改任务的问题。
task = agent.create_task(
"Explain to me what is Lora and why it's being used."
"Are existing solutions not good enough?"
)
step_output = agent.run_step(
task.task_id, input="Explain to me the dataset used to fine-tune in the Lora paper."
)
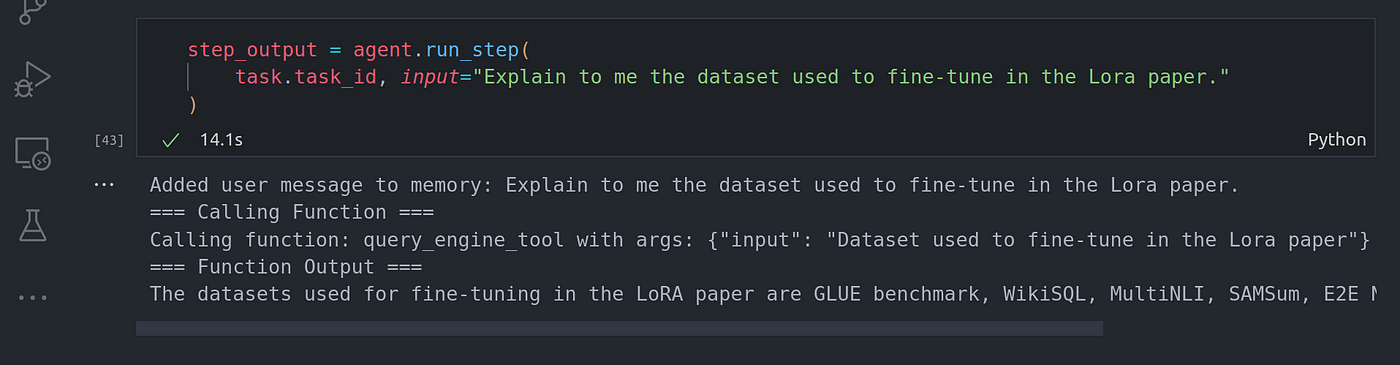
Image By Code With Prince
图片来源:Prince 代码
We need to check if it’s the last step, this is important or you’ll get an error. I don’t know why they had to do that.
我们需要检查这是否是最后一步,这一点很重要,否则就会出错。我不知道他们为什么要这么做。
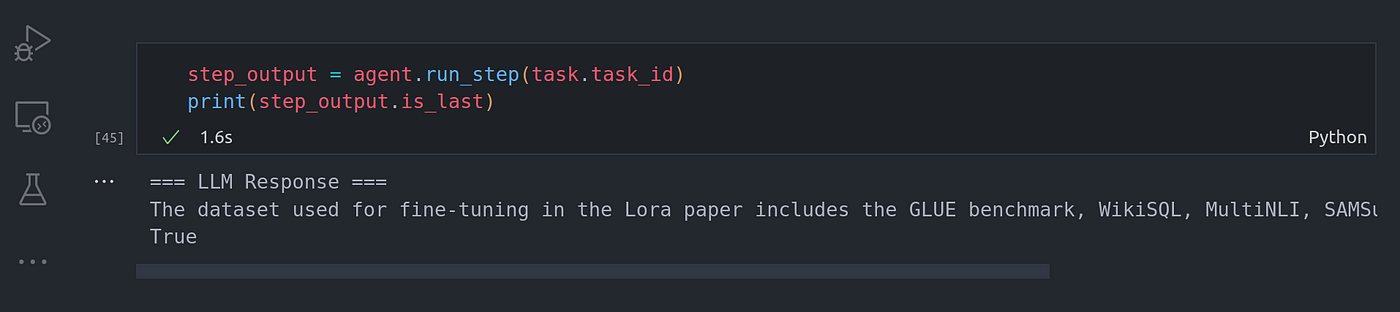
Image By Code With Prince
图片来源:Prince 代码
Once done, we can go ahead to getting the finalized response:
完成后,我们就可以继续得到最终答复了:
response = agent.finalize_response(task.task_id)
print(str(response))

Image By Code With Prince
图片来源:Prince 代码
Conclusion 结论
Congratulations for making it this far. In this article post, we have gone over how to work with a multi-step reasoning loop in an agentic RAG system. We did not only see the high-level implementation, but also the low-level working of the multi-step reasoning loop and being able to provide feedback to the agent (human feedback in the loop).
恭喜你走到了这一步。在这篇文章中,我们介绍了如何在代理 RAG 系统中使用多步骤推理循环。我们不仅看到了高层次的实现,还看到了多步骤推理循环的底层工作,以及向代理提供反馈(循环中的人为反馈)的能力。
Hope this article now provides you with a clear understanding of an agentic multi-step reasoning capability. In the next article, we’ll go over how to perform RAG capabilities using multiple documents.
希望这篇文章能让你清楚地了解代理多步骤推理能力。在下一篇文章中,我们将介绍如何使用多个文档执行 RAG 功能。
**Other platforms where you can reach out to me:
其他可以联系我的平台:**
**_Happy coding! And see you next time, the world keeps spinning.
编码快乐!下次再见,世界在继续转动。_**